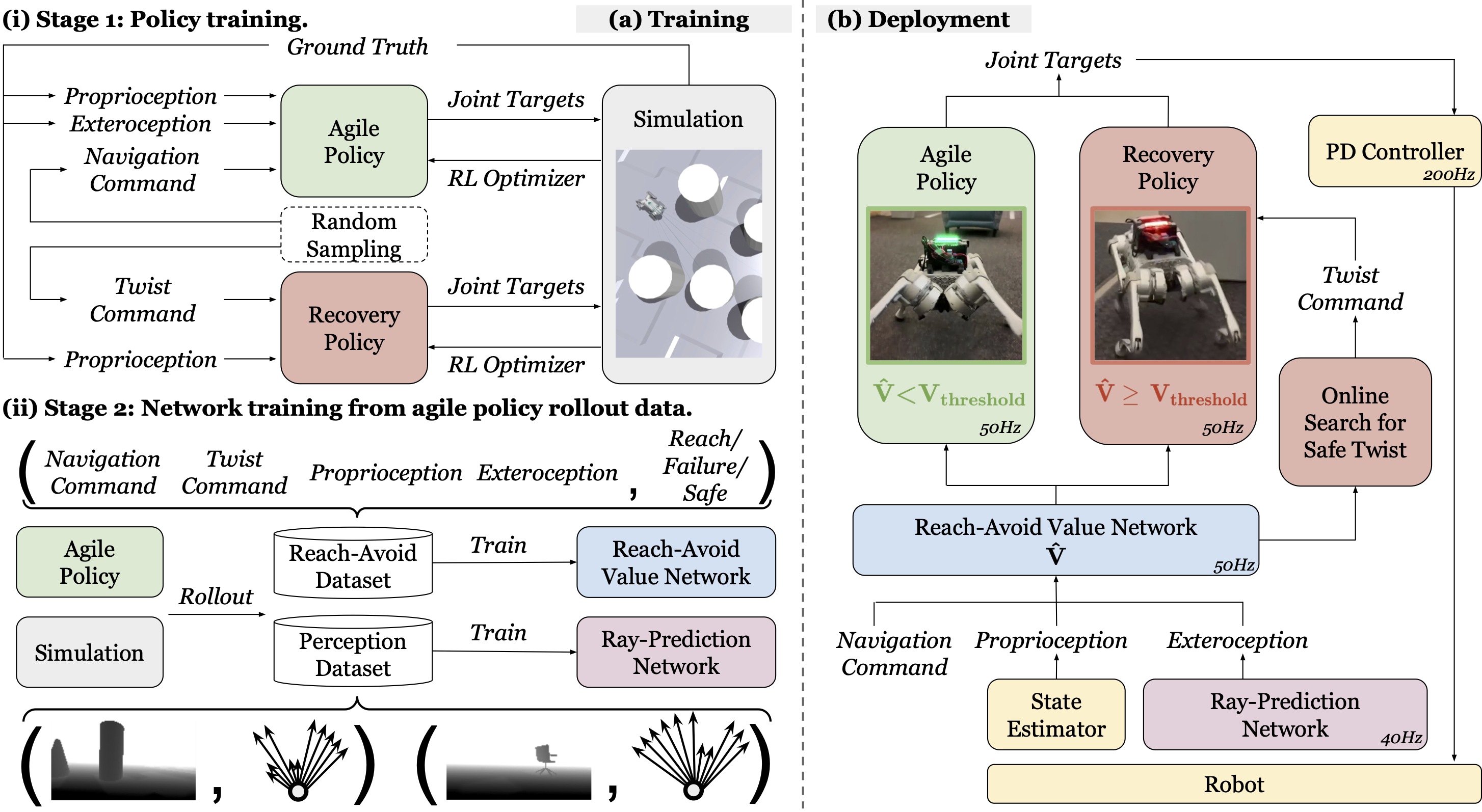
Method
ABS framework
- Training architecture: There are four trained modules within the ABS framework:
- Agile Policy is trained to achieve the maximum agility amidst obstacles;
- Reach-Avoid Value Network is trained to predict the RA values conditioned on the agile policy as safety indicators;
- Recovery Policy is trained to track desired twist commands (2D linear velocity and yaw angular velocity) that lower the RA values;
- Ray-Prediction Network is trained to predict ray distances as the policies' exteroceptive inputs given depth images.
- Deployment architecture: The dual policy setup switches between the agile policy and the recovery policy based on the estimated V̂ from the RA value network:
- If V̂ < Vthreshold, the agile policy is activated to navigate amidst obstacles;
- If V̂ ≥ Vthreshold, the recovery policy is activated to track twist commands that lower the RA values via constrained optimization.